Sonette Yzelle asked the following question on the Sakai Developer list.
Hi All,
I am a developer at UNISA. We have to decide what will be the best framework to use in future. We want to become more involved/contribute in Sakai.
We are using struts currently but must decide now if we are going to use RSF, VM, continue using struts or use something else. We don’t want to build in unnecessary complication in our codes as we battle to get developers with the right skills and we had 3 resignation in the last 2 months. Questions that game up during our discussion were:
* Will struts be accepted by the Sakai Community?
* What is the general feeling about RSF in the Sakai Community? I found that some hate it and others love it, but I guess you get that with any programming language.
* Can any framework be used in Sakai as long as the tool work?
Do you have any suggestions to help us with our decision please?
— Sonette
Monthly Archives: July 2008
Progress on SAK-13584 – MailArchive Performance Improvements
I got the conversion working and all the code checked in. I used the Ian/Jim conversion gadget. Initially it looked like a crazy contraption. It turns out to be pretty cool – just undocumented – and the way Jim/Ian used it in Content was totally Ninja-warrior.
Luckily my new conversion code is a *much* better sample to work from – because it is simple. Some documentation should be written.
So it is now off to Tony for testing. More detail below.
Now I am off to go get my motorcycle gear from www.ridersdiscount.com. So for the rest of the day – call the cell.
Mail Archive Tool – Improvements for 2.6 (SAK-13584)
Hot on the heels of my MailArchive Performance Improvements for 2.5 to handle large mail sites without chewing up memory and processor, I have pretty much completed an Alpha version of the next round of MailArchive performance improvements based on a database conversion extracting fields from the XML. I was hacking on this in Paris, Barcelona, Cambridge, on the plane to the US and on the bus to Lansing.
Here are the relevant JIRAs:
http://jira.sakaiproject.org/jira/browse/SAK-13584 (2.6 improvements)
http://jira.sakaiproject.org/jira/browse/SAK-11544 (2.5 improvements)
I will check it into a set of branches soon for some more extensive testing across more databases.
Here is a summary of the changes:
– Fully normalized the MAILARCHIVE_MESSAGE table – all fields are in columns now. The XML must stay for a while (more below) but it is not used for any search or selection.
– Added Aaron’s GenericDAO concepts to org.sakaiproject.javax – with some improvements. Order and Restrictions are unchanged. Search has become Query. I added a searchString property to Query and added a few setters which were missing.
– Changed the BaseDbDouble ORM code to support the new genericDAO pattern when it sees a fully normalized table. When it sees a search, it uses a where clause instead of scanning all the data in Java. Also it understand the notion of search fields as well as order by fields. And from the 2.5 modification, paging is implicit throughout as well. Now the BaseDoubleDb can get either a count of messages or a list of messages using Search, Order, and Paging with a single DB query that returns *exactly* the right row set and nothing more.
– Changed the MailArchiveTool to use as little session state as possible. I moved some information into REST-based URLs. Also any heavywieght information is put into Context, never in session. This leaves the MailArchiveTool with a small session state with a few strings and integers – and everything left in Session should be trivially serializable.
This restores all functionality of the MailArchive tool regardless of the size of the message corpus. Each screen display is exactly one SQL statement to pull back *exactly* the required data searched and sorted in the database.
This makes it *REALLY* easy to come up with a really efficient webservice or sdata feed for Mail Archive – since you can search, order, and scope data above the API – you can produce *exactly* the JSON you need to implement a sweet dynamically scroll view of MailArchive where as you scroll off the bottom, the next 100 or so messages come from the server.
This also allows very efficient retrieval of messages for something like the SOLO offline Sakai client that Psybergate has produced with UNISA and NWU or other Google Gears views of a site’s MailArchive Corpus. When SOLO meets SDATA at some future point in time – it might be a shot “heard round the world”.
In general, I am pretty excited about the possibility of moving a legacy tool from being XML-based- to be very efficient and REST friendly. It was not that hard – once I fixed the DB layer to understand Query – I was mostly removing code from the Controller/View code (MailboxAction.java is much smaller now).
I really wanted to get the session to nearly zero and have Restful URLs for everything. But interestingly because the portlet model has this notion of Action and View being separated (often by a redirect on post), it makes it harder to put all of your state into the URL :(. So the compromise is a bit of session (as little as possible and all serializable) use REST urls as much as possible to let the back button work a little better – at least when you go back and click on a different button in a list view – you get the right message :). I need to do more study on this. JSR-168 has some features that make the back button more friendly than the old Jetspeed pattern.
The problem with the back button is really traced more to the Jetspeed 1.0 portlet pattern – it is not something inherent in using Velocity. And interestingly, this is another moment in time where my respect for the thought that went into JSR-168 grows.
I will begin checking this stuff in soon. I need to take a brain break and think about something else for a day or so and then review it before I make all my branches so folks can take a look.
Sakai Conference – Paris
Wow – I finally get a few minutes to blog about Paris. I had two talks which are listed at the end. Initially a few reflections.
This was our second European conference – I think that it worked well – we met many new faces – this is always important for open source. I wish we could have gone sometime other than the middle of summer – there were too many tourists in Paris :).
Probably the most exciting part of this conference was the participation of teachers. Thanks to Josh Baron of Marist – we had a great contest for the best use of Sakai with two wonderful winners who gave wonderful presentations. The coolest thing was the fact that half the room was filled with developers and tech support folks.
Usually we are told what is wrong or what needs fixing or what is hard to use about this software that we work so hard to make better. It was nice to hear from someone who *loved* using Sakai and felt that Sakai enabled them to teach better. I know that I could not teach the way I want to teach on any other learning management system – period. So while we are continuously bombarded about how we can improve (aka criticisim) – we need to remember that what we have here is pretty damn functional as we stand.
The other amazing thing was the amount of innovation *around* Sakai – the SOLO offline system using Google GWT and Gears was amazing, the IMS ePortfolio export from Edia was amazing, seeing folks working on the Open Syllabus in GWT was neat as well. Of course the MyCamTools stuff just gets better and better every time I see it.
I had spent some time working on McGraw-Hill’s Katana before Paris and helped write their install documentation. I like the MHE approach because it gives teachers control over the organization and arrangement of the content and allows them to edit the content other than the learning modules. The large and complex learning modules are served from the MHE servers. The software is free, the content is free for teachers t explore – and only the students pay (like a book) when the teacher decides to use the content. Very cool. The Katana content is not part of a book – it is useful materials that can be used with any book – McGraw-Hill or otherwise. I want to get MHE to use IMS LTI as well so we can quickly get Katana Content into Blackboard and Moodle and other places as well.
The whole Michigan team had some good talks with Michael Feldstein and John Lewis about doing some early work with the IMS Learner Information Services spec. I would really like to see that happen.
The food was great – I went to the Eiffel Tower and Notre-Dame and not much else tourist wise.
I am really looking forward to the regional conferences for Sakai now that we have moved to an annual conference. I have a feeling that the Virginia Tech teaching with Sakai meeting will be awesome.
Here are my talks:
Teaching in the Open
http://www-personal.umich.edu/~csev/talks/2008/2008-06-30-teaching-open.pdf
Functionality Mashup – IMS Learning Tools Interoperability
http://www-personal.umich.edu/~csev/talks/2008/2008-07-03-lti-sakai.ppt
More fun in Barcelona – Google Summer of Code Meeting
 My good fortune continues. today I spent the day at Marc Alier’s home on the north side of Barcelona near the beach. The first part of the day was spent talking and meeting everyone over a long lunch that included several kinds of Cava, snails, and Risotto.
My good fortune continues. today I spent the day at Marc Alier’s home on the north side of Barcelona near the beach. The first part of the day was spent talking and meeting everyone over a long lunch that included several kinds of Cava, snails, and Risotto.
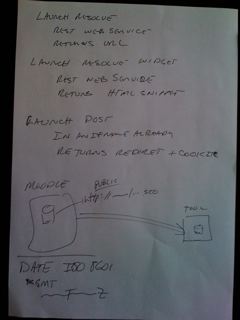
Then Jordi and I spent about an hour designing the Moodle Module and Filter for the Simple LTI consumer tool. We talked about the structures and what additional features to add if we got done early. The basic outline was to work on the Launcher, the admin configuration of final configuration variables, virtual tools, a two-layer identity data sandbox mechanism, and a set of admin tracking, monitoring, white-list/black-list features under the control of the administrator.
 Then Marc, Jordi, and I went to the beach on bikes. It was very nice and warm and we took a short swim. The cardinality of the set of female beach clothing configurations was one larger than on any other beach I had visited before – so that was an interesting experience.
Then Marc, Jordi, and I went to the beach on bikes. It was very nice and warm and we took a short swim. The cardinality of the set of female beach clothing configurations was one larger than on any other beach I had visited before – so that was an interesting experience.
When we got back we had Horchata and ice cream and talked about Texas Hold-em poker and how America might change as gas prices continue to increase.
P.S. Spain has already lowered their national speed limit to conserve fuel – making all unhappy – which might come to the US sooner than we think.
The Starfish and the Spider – The Unstoppable Power of Leaderless Organizations
I am like the luckiest guy in the world – after a great week in Paris with my second family of the Sakai community I was able to come to spend the weekend in Barcelona with some last minute arrangements and meet some new tech-geek friends.
After a long day of talking eating, drinking, talking and drawing architecture diagrams on napkins – we were going back to my hotel. Earlier I had told the group all about one of my favourite books – “The Innovators Dilemma”.
http://www.claytonchristensen.com/publications/
On the drive to the hotel one of my new pals told me of one of his favourite books titled “The Starfish and the Spider – The Unstoppable Power of Leaderless Organizations”.
http://www.starfishandspider.com/
Here is the short synopsis – the Spider is a hierarchical organization where each piece does its precise part in well-organized concert with the other parts of the spider. You can kill a Spider by putting a tiny pin through the Spider at that one place where it is all controlled.
The Starfish by contrast is a collective of pretty independent units. While none of the bits can stand alone – you can cut off a whole leg of a starfish and it will grow back – or if you chop a starfish in half you will end up with two starfishes. So while a starfish needs some minimal sized chunk to survive – it is pretty robust when it is injured and no single injury can kill the Starfish.
The book talks about how the Spanish invaders quickly conquered the Aztecs and Incas with 100 soldiers by figuring out the leader and killing the leadership (Spider killed by a tiny pin). However as they moved north, the encountered the Apaches. The Apaches were an open source project derived form the original NCSA httpd server. (Sorry – I slipped into the wrong story for a moment there).
The Apaches were a decentralized free society that operated in a collective manner but where participation in collective action was voluntary. So there was no real leader of the Apaches. When the invaders found someone who *looked like a leader* and killed that person – it was just the old medicine man – who was the spiritual leader- and while the tribe certainly must have missed the medicine man and hearing long stories about the ways of the ancient ones around the campfire – ultimately the loss of the medicine man did not stop the Apaches from organizing to wage war and chopping the Spaniards into small pieces.
After a while the Spaniards figured out that sneaking 100 soldiers into the middle of a big gathering of Apaches and killing one medicine man – just resulted in a lot of Spaniard pate’.
So how did the Apaches finally lose? According to the book, the United States much later turned the Starfish *into* a Spider. They took only a few of the Apaches – told them they were “special” – and gave these new special Apaches some cows. The ownership of a cow proved to be pretty cool – milk, baby cows for Veal Parmesan, Ruth Chris Filet Mignons cooked at 1800 degrees soaked in butter – all that. Feeding the whole tribe Ruth Chris steaks got one a lot of street cred that could be used later when decisions needed to be made.
The cows caused structure to appear in the society – and folks started keeping track of who was up and who was down – the Apaches were no longer equals in a loose, flexible, and dynamic collective – there was a class structure – and who you were and where you fit in the cow owner society started to matter and structure formed.
While the Starfish is generally pretty resilient in the face of obvious and seemingly damaging frontal attacks, it is fascinating how collective adaptive organizations (Starfish) can slowly be transformed into hierarchical static organizations (Spiders) by coming in the back door – intending to “help” and treating some members of the collective as “special”.
In Paris doing some Code (SAK-13886)
Well – there is a performance issue in the portal code in Sakai 2.5. There are more queries to the SAKAI_SITE_PROPERTY in Sakai 2.5 than in 2.4.
In looking at things there were several instances of “too many queries” – not just from 2.5 – but for a few features that were added to portal between 2.3 and 2.5.
So I pored over the code for the last three days and figured out what kind of optimization which had already been done – and figure out where bits were leaking through the prior optimization.
I talked to Aaron and Ian – and came up with two solutions – one using memcache for the properties and another using thread local.
I think that this will be important for Sakai 2.5 sites – My guess is that in the summer many are not noticing the additional query load on the main portal displays. Without these patches things will likely slow down a bit and/or consumer more resources.
I initially made a property to control which tables the properties get cached in memory – my guess is that particularly for 64-bit JVM’s this should be
DbFlatPropertiesCache=:all:
But at a minimum this is needed:
DbFlatPropertiesCache=:SAKAI_SITE_PROPERTY:
After some testing and experience we should figure out which of these two should be the default. I think that the methodology (suggested by Ian) is to look at query patterns and see if you are seeing too many hits on tables like:
SAKAI_SITE_PAGE_PROPERTY, SAKAI_SITE_TOOL_PROPERTY, SAKAI_SITE_GROUP_PROPERTY, …
Then simply add them to the list in preferences – and see if things get better.
This is a nice, clean, short-lived memcache – and it is automated perfectly when properties are changed on the same server (i.e. when an instructor makes a change and presses refresh – the display will be perfect – instantly reflecting the changes).
The Thread Local code is obvious and must be done. It simply makes sure that the portal only gets the list of visitable sites once from the database.
Both of these mods are really simple and clean and should be trivial to review.
I currently have some print statements that can be uncommented if folks want to watch the new caches in action.
Once some testing happens – I will remove these before sending it to trunk.
Now this is done, I can start working on my talk for tomorrow about functionality mashup.
Here is my message to the dev list about it.