The University as a Cloud: Openness in Education
Dr. Charles Severance
University of Michigan School of Information
This is an extended abstract for a keynote I recently gave in Andora. The slides for the presentation are available on SlideShare.
Warning: I caution you to read this with an understanding that this is not a precise academic treatise backed by deep facts, figures, and data. It is an exaggerated perspective that is intended to make people think. I would also point out that I have little respect for keynote speakers that simply say “all is lost”. For me, this is not an “all is lost” or “higher education will die a horrible death in the next five years” keynote. Frankly – those gloom-and-doom keynotes are a dime-a-dozen, uncreative, and complete crap. I think that those faculty and universities that see the trends I am talking about and evolve to a more open approach to their teaching, research, and engagement with their stakeholders will thrive. So this is an optimistic outlook even though it seems rather negative in the first part.
In this keynote, I explored the nature of the changing relationship between universities and their governments and propose ideas as to how faculty may need to evolve their strategies over the next decade or so around teaching and research to insure a successful career for themselves as well as continued success for higher education in general. The keynote was not intended as presentation of the facts of the current situation – but rather to get people talking about why openness may soon move from optional to nearly required in higher education.
Up to the 1900, the world was relatively unconnected and higher education was only available to a select wealthy few. The pace of research and innovation was relatively slow and much of the academic research was focused on investigating the natural world and gaining increasing understanding in areas like physics, electricity, civil engineering, and metallurgy. Efforts like the Eiffel Tower, electric light, the first powered flight, radio, and the Titanic were the “grand challenges” of the time.
World War II caused a great deal of research into how the “technology” discoveries in the 1800’s and early 1900’s could be used to gain an advantage in war. If you compare trench warfare with rifles at the beginning of World War I with the technology of aircraft carriers, jet engines, rockets, and nuclear weapons by the end of World War II in the 1940s, it was an amazing collaboration between governments, scientists, and engineers to develop these sophisticated technologies in such a short period.
After the war it was clear that the “winner” of the war was the side with the quickest minds and the most scientists. Most countries around the world saw higher education, particularly research-oriented higher education as essential to national security going forward. This resulted in a great expansion of the size and number of research universities around the world. Research funds were available from governments to reward successful scientists and support the next generation of PhD. students.
In order to break the Axis encryption during World War II, scientists at Bletchley Park and elsewhere invented the first high-speed electronic computers and demonstrated the strategic importance of efficient communication and organizing and processing large amounts of information. In the United States after the war, the National Science Foundation was created to fund research into these new technologies. The military also made direct investments in funding academic research through agencies like the United States Advanced Research Projects Agency (ARPA).
From the 1950’s through 2000, governments saw significant payoff in investing in academic research as academics provided solutions to problems first in computing technology, then networking technology as embodied in the Internet and then advances in information management as embodied in the World-Wide-Web. Academic research was an essential element of the progress in the last half of the twentieth century. Academics funded through agencies like the National Science Foundation and Advanced Research Projects Agency (ARPA) performed research that was of strategic value to governments around the world.
With the bounty of research funding during the latter part of the 20th century, there was an increasing need to efficiently allocate research funds to the most worthy scientists. An extensive network of peer-reviewed journals and high-quality conferences are used to award research funds to those who are most worthy. In this environment, a research faculty member must spend their early career furiously publishing research in journals to develop a sufficient reputation within their field so as to assure a regular stream of research funding. Those who can successfully navigate this gauntlet are rewarded with tenure.
After the year 2000 with computing, networking, and the web well developed, there are fewer research areas that are of strategic value to governments. Research funding continues albeit at lower levels with a focus on research that benefits society more broadly such as health-related areas. While government funded research is not going away, the overall level of investment will naturally be lower if research is not seen as a strategic military priority as it was in the second half of the 20th century.
Furthermore as the Internet, web and other technologies have lead to increasingly global manufacturing and markets, the first-world countries are experiencing a slow decline in their economic advantage relative to the rest of the world. This has put governments under pressure to spend shrinking public funds on the most important pressing needs facing society. Around the world the general trend is for governments to reduce the public funding available to support teaching and research.
It is not likely that these reductions in government teaching and research funding levels are “temporary”. It is more likely that universities and colleges will need to rely more on other sources of funding in the long-term. These other sources will likely come from three areas: (a) tuition, (b) donations from alumni, and (c) research funding from industry.
If we assume this hypothesis for the sake of argument, then what would be the best strategy for faculty and administrators to survive and thrive in this new funding environment?
The simple answer that I think will become an increasing element of higher education’s strategy is one of openness. Higher Education must more directly demonstrate its value to governments, students, private industry, and the rest of society. The number of journal papers, which for the past 60 years is the most important measure of the value of a faculty member will have far less value for this new set of stakeholders and possible funders for higher education. Faculty must get their ideas into the open and do so quickly to have real impact on the real problems that are facing our world today. Hiding the best teachers at a university in a small face-to-face classrooms will also not lead to broadly perceived value for the faculty members and the institution.
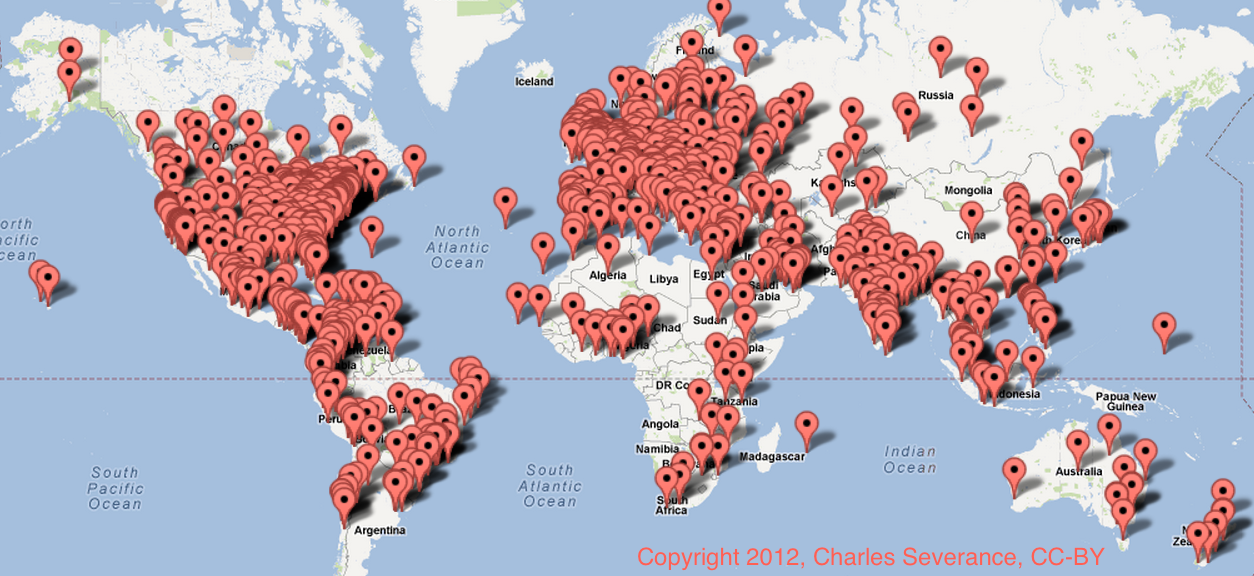
Higher education must compete in public and in the open. The recent excitement surrounding Massive Open Online Courses (MOOCs) is but one example of how being open and doing something for free shows the value of universities to a broader populace. This is an example of helping amazingly talented teachers at outstanding schools teach in the open – and it has had a very positive worldwide impact for those universities that have participated in the current MOOC efforts.
We need to see this kind of direct openness between universities and their faculty with the rest of society in research areas as well. Ideas need to be made more public and communicated clearly in a way that all people can understand them – rather than cloaked in obtuse mathematics in dusty journals.
Of course the trends I describe in the keynote and this paper are exaggerated to make my point. Nothing moves so quickly so I am not suggesting that young faculty immediately stop writing journal articles. That would be harmful to their career and tenure because the new systems of determining value and measuring impact are not in place at most universities. But young faculty should begin to compliment their traditional research and teaching output with more open forms of teaching and publication so they are prepared to participate in new ways of demonstrating value to society in the future.
Comments welcome.
P.S. I was invited to expand on this notion as an invited submission to a special issue of a journal. That would be ironic. A journal article about the shrinking value of journal articles.