This is a report of my UMSI monthly article of the same title –
http://monthly.si.umich.edu/2012/10/18/all-the-worlds-a-classroom/
This summer it was my great pleasure to teach an online non-credit course titled Internet History, Technology, and Security to a students around the world at no cost using the Coursera platform for large-scale online courses. Over 49,000 students registered for the free class, over 16,000 attended the first week’s lecture and over 4900 students earned a certificate at the end of the 10-week course. It would take 32 years of teaching our SI502 foundations course on Networked Computing to interact with that many students.
For that first course, I chose to use several weeks of SI502 that focused on how the network was built over time and how it functions today and expanded it to become a 10-week course. I chose this material because it is fun, engaging, and very well suited for a video format. But more importantly, I wanted to create a course about technology that would be accessible to learners of all levels and all languages around the world. I also wanted a course that showcased the School of Information’s core competency of “connecting people, information, and technology in more valuable ways”.
The course started by looking at the code breaking efforts during World War II in the United States and the UK. It was a perfect example of having lots of data and using computing to transform that raw, encrypted, and seemingly meaningless data first into information and then ultimately into knowledge. Because of the heavy use of advanced encryption techniques for wartime communications, high-speed computation devices were developed to “crack” the encryption. Initially those devices were electromechanical and then later to increase the speed of the devices, the first electronic computers were invented and built under the top-secret wartime conditions at Bletchley Park. Bletchley Park was a beehive of activity with over 10,000 people, many thousands of encrypted messages (information) and hundreds of computers working 24 hours per day (technology).
The course followed the history through the post war period, through to the current day featuring interviews of many innovators ranging from the co-inventor of the World-Wide-Web (Robert Calliau) through the founder of Amazon (Jeff Bezos).
Once we had viewed the Internet through a historical lens, we went back and took another look at the Internet through a more technical lens, examining how packets work, the Link Layer, Internetwork layer (IP), the Transport Layer (TCP), and the Application Layer.
I saw this course as far more than just another course. To me it represented so much of what it means to be part of the School of Information at the University of Michigan and I tried to reflect the values of SI throughout the course material and how I approached and taught the course. I wanted to make all of the technical material in the course accessible to learners of all levels. The course lecture and video materials were translated by the students (crowd sourcing) into over 30 languages and we had students from all over the world and nearly every single country was represented. I made sure to teach the course in a way that would be accessible to non-English speakers as well as those with slow or unreliable network connections.
Another exciting part of the course was how the students became a self-organizing social learning community. With over 10,000 students active throughout most of the course, there was literally no way that I as the faculty member could help each individual student with a technical issue or problem understanding the materials. The students were amazingly wonderful at helping each other, forming study groups, and some even took the initiative produce supporting course materials and reading lists for the class. Because of so much proactive student involvement, my workload was surprisingly low.
One of the issues in online courses is the sense of loneliness and isolation. One experiment I tried was to have “office hours” in various cities as I travelled in the late summer and early fall. I had office hours in New York City, Los Angeles, Wilmington, NC, Ann Arbor, Chicago, Memphis, Washington, DC, and Seattle WA. The office hours had 2-15 students show up in a local coffee shop and we talked about the class and how it could be improved. The students thought it was cool to meet their online instructor and that I was being very giving of my time. But in actuality I did the office hours because I wanted to see and meet my students – or at least some of them. It helped me maintain my own motivation to know that my students were real and not just numbers and data inside of a computer. I learned so much about how to better teach the course from these interactions. I have upcoming office hours in Seoul, South Korea, Barcelona Spain, Denver Colorado, and Amsterdam as part of my travel plans for the fall.
Students who completed the course with a passing score will receive an online certificate of achievement from Coursera. Students can print out the certificate or link to it in their resumes. I decided to go a step further and offer to sign their certificates if they would send them to me at the School of Information with a self-addressed stamped envelope. I have warned the Dean’s office that they might be receiving 4,900 pieces of mail for me over the next few months. Like everything in the course, for me this is just another experiment in how far we can expand the boundaries of this new form of interacting in the context of teaching the world.
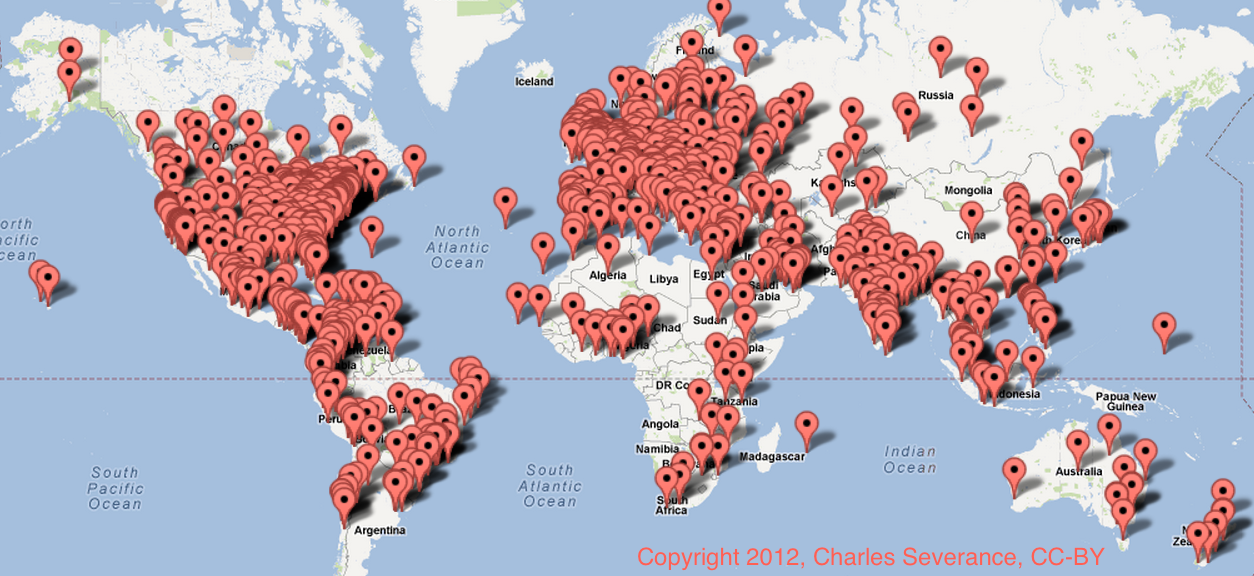
I did a summary lecture for the course and put it up on YouTube that you are welcome to watch to see my reflections on the course as well as a presentation of the student demographics and retention statistics for the course. You can also take a look at an interactive map of the geographic distribution of the students in my course from a blog post that I wrote.
And if you found this interesting, the course will be offered again soon and you are welcome to sign up and join us online. I hope to see you on the net.