Once it became easy to retrieve documents and parse documents
over HTTP using programs, it did not take long to develop
an approach where we started producing documents that were specifically
designed to be consumed by other
programs (i.e. not HTML to be displayed in a browser).
The most common approach when two programs are exchanging data across
the web is to exchange the data in a format called the ``eXtensible Markup
Language'' or XML.
13.1 eXtensible Markup Language - XML
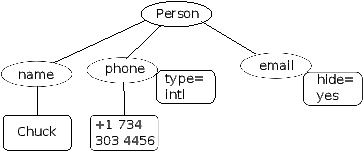
XML looks very similar to HTML, but XML is more structured
than HTML. Here is a sample of an XML document:
<person>
<name>Chuck</name>
<phone type="intl">
+1 734 303 4456
</phone>
<email hide="yes"/>
</person>
Often it is helpful to think of an XML document as a tree structure
where there is a top tag person and other tags such as phone
are drawn as children of their parent nodes.
13.2 Parsing XML
Here is a simple application that parses some XML
and extracts some data elements from the XML:
import xml.etree.ElementTree as ET
data = '''
<person>
<name>Chuck</name>
<phone type="intl">
+1 734 303 4456
</phone>
<email hide="yes"/>
</person>'''
tree = ET.fromstring(data)
print 'Name:',tree.find('name').text
print 'Attr:',tree.find('email').get('hide')
Calling fromstring converts the string representation
of the XML into a 'tree' of XML nodes. When the
XML is in a tree, we have a series of methods which we can call to
extract portions of data from the XML.
The find function searches through the
XML tree and retrieves a node that matches the specified tag.
Each node can have some text, some attributes (i.e. like hide) and
some ``child'' nodes. Each node can be the top of a tree of nodes.
Name: Chuck
Attr: yes
Using an XML parser such as ElementTree has the advantage
that while the XML in this example is quite simple, it turns
out there are many rules regarding valid XML and using
ElementTree allows us to extract data from XML without
worrying about the rules of XML syntax.
13.3 Looping through nodes
Often the XML has multiple nodes and we need to write a loop
to process all of the nodes. In the following program,
we loop through all of the user nodes:
import xml.etree.ElementTree as ET
input = '''
<stuff>
<users>
<user x="2">
<id>001</id>
<name>Chuck</name>
</user>
<user x="7">
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff = ET.fromstring(input)
lst = stuff.findall('users/user')
print 'User count:', len(lst)
for item in lst:
print 'Name', item.find('name').text
print 'Id', item.find('id').text
print 'Attribute', item.get('x')
The findall method retrieves a Python list of sub-trees that
represent the user structures in the XML tree. Then we can
write a for loop that looks at each of the user nodes, and
prints the name and id text elements as well as the
x attribute from the user node.
User count: 2
Name Chuck
Id 001
Attribute 2
Name Brent
Id 009
Attribute 7
13.4 Application Programming Interfaces (API)
We now have the ability to exchange data between applications using HyperText
Transport Protocol (HTTP) and a way to represent complex data that we are
sending back and forth between these applications using eXtensible
Markup Language (XML).
The next step is to begin to define and document ``contracts'' between
applications using these techniques. The general name for these
application-to-application contracts is Application Program
Interfaces or APIs. When we use an API, generally one program
makes a set of services available for use by other applications
and publishes the APIs (i.e. the ``rules'') that must be followed to
access the services provided by the program.
When we begin to build our programs where the functionality of
our program includes access to services provided by other programs,
we call the approach a Service-Oriented Architecture or SOA.
A SOA approach is one where our overall application makes use of
the services of other applications. A non-SOA approach is where the
application is a single stand-alone application which contains all of the
code necessary to implement the application.
We see many examples of SOA when we use the web. We can go to a single
web site and book air travel, hotels, and automobiles all from a
single site. The data for hotels is not stored on the airline computers.
Instead, the airline computers contact the services on the hotel computers
and retrieve the hotel data and present it to the user. When the user
agrees to make a hotel reservation using the airline site, the airline site uses
another web service on the hotel systems to actually make the reservation.
And when it comes to charge your credit card for the whole transaction,
still other computers become involved in the process.
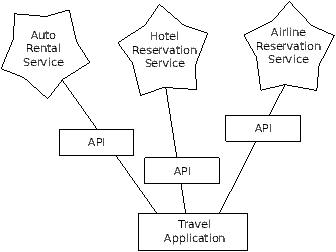
A Service-Oriented Architecture has many advantages including: (1) we
always maintain only one copy of data - this is particularly important
for things like hotel reservations where we do not want to over-commit
and (2) the owners of the data can set the rules about the use of their
data. With these advantages, a SOA system must be carefully designed
to have good performance and meet the user's needs.
When an application makes a set of services in its API available over the web,
we call these web services.
13.5 Twitter web services
Note: Since this section was written, Twitter has
dramatically changed the format and rules for the use of its API.
So the code that uses the Twitter API will no longer work. It
still shows how one would work with an XML-based API in general.
You can view the Twitter API documentation at
http://apiwiki.twitter.com/. The Twitter API is an example
of the REST style of web services.
We will focus on the Twitter API
to retrieve a list of a user's friends and their statuses. As an
example, you can visit the following URL:
http://api.twitter.com/1/statuses/friends/drchuck.xml
To see a list of the friends of the twitter account drchuck.
It may look like a mess in your browser. To see the actual XML
returned by Twitter, you can view the source of the returned
``web page''.
We can retrieve this same XML using Python using the urllib
utility:
import urllib
TWITTER_URL = 'http://api.twitter.com/l/statuses/friends/ACCT.xml'
while True:
print ''
acct = raw_input('Enter Twitter Account:')
if ( len(acct) < 1 ) : break
url = TWITTER_URL.replace('ACCT', acct)
print 'Retrieving', url
document = urllib.urlopen (url).read()
print document[:250]
The program prompts for a Twitter account and opens the URL
for the friends and statuses API and then retrieves the
text from the URL and shows us the first 250 characters of
the text.
python twitter1.py
Enter Twitter Account:drchuck
Retrieving http://api.twitter.com/l/statuses/friends/drchuck.xml
<?xml version="1.0" encoding="UTF-8"?>
<users type="array">
<user>
<id>115636613</id>
<name>Steve Coppin</name>
<screen_name>steve_coppin</screen_name>
<location>Kent, UK</location>
<description>Software developing, best practicing, agile e
Enter Twitter Account:
In this application, we have retrieved the XML exactly as if it were
an HTML web page. If we wanted to extract data from the XML, we
could use Python string functions but this would become pretty complex
as we tried to really start to dig into the XML in detail.
If we were to dump out some of the retrieved XML it would look roughly as follows:
<?xml version="1.0" encoding="UTF-8"?>
<users type="array">
<user>
<id>115636613</id>
<name>Steve Coppin</name>
<screen_name>steve_coppin</screen_name>
<location>Kent, UK</location>
<status>
<id>10174607039</id>
<source>web</source>
</status>
</user>
<user>
<id>17428929</id>
<name>davidkocher</name>
<screen_name>davidkocher</screen_name>
<location>Bern</location>
<status>
<id>10306231257</id>
<text>@MikeGrace If possible please post a detailed bug report </text>
</status>
</user>
...
The top level tag is a users and there are multiple user tags
below within the users tag. There is also a status tag below
the user tag.
13.6 Handling XML data from an API
When we receive well-formed XML data from an API, we generally use
an XML parser such as ElementTree to extract information from
the XML data.
In the program below, we retrieve the friends and statuses from
the Twitter API and then parse the returned XML to show the first
four friends and their statuses.
import urllib
import xml.etree.ElementTree as ET
TWITTER_URL = 'http://api.twitter.com/l/statuses/friends/ACCT.xml'
while True:
print ''
acct = raw_input('Enter Twitter Account:')
if ( len(acct) < 1 ) : break
url = TWITTER_URL.replace('ACCT', acct)
print 'Retrieving', url
document = urllib.urlopen (url).read()
print 'Retrieved', len(document), 'characters.'
tree = ET.fromstring(document)
count = 0
for user in tree.findall('user'):
count = count + 1
if count > 4 : break
print user.find('screen_name').text
status = user.find('status')
if status :
txt = status.find('text').text
print ' ',txt[:50]
We use the findall method to get a list of the user
nodes and loop through the list using a for loop.
For each user node, we pull out the text of the screen_name node
and then pull out the status node. If there is a status
node, we pull out the text of the text node and print the first 50
characters of the status text.
The pattern is pretty straightforward, we use findall and find
to pull out a list of nodes or a single node and then if a node is a complex
element with more sub-nodes we look deeper into the node until we reach the
text element that we are interested in.
The program runs as follows:
python twitter2.py
Enter Twitter Account:drchuck
Retrieving http://api.twitter.com/l/statuses/friends/drchuck.xml
Retrieved 193310 characters.
steve_coppin
Looking forward to some "oh no the markets closed,
davidkocher
@MikeGrace If possible please post a detailed bug
hrheingold
From today's Columbia Journalism Review, on crap d
huge_idea
@drchuck #cnx2010 misses you, too. Thanks for co
Enter Twitter Account:hrheingold
Retrieving http://api.twitter.com/l/statuses/friends/hrheingold.xml
Retrieved 208081 characters.
carr2n
RT @tysone: Saturday's proclaimation by @carr2n pr
tiffanyshlain
RT @ScottKirsner: Turning smartphones into a tool
soniasimone
@ACCompanyC Funny, smart, cute, and also nice! He
JenStone7617
Watching "Changing The Equation: High Tech Answers
Enter Twitter Account:
While the code for parsing the XML and extracting the fields
using ElementTree takes a few lines to express what
we are looking for in the XML, it is much simpler than trying
to use Python string parsing to pull apart the XML and find
the data elements.
13.7 Glossary
- API:
- Application Program Interface - A contract between
applications that defines the patterns of interaction between
two application components.
- ElementTree:
- A built-in Python library used to parse XML data.
- XML:
- eXtensible Markup Language - A format that allows for
the markup of structured data.
- REST:
- REpresentational State Transfer - A style of Web Services
that provide access to resources within an application using the HTTP
protocol.
- SOA:
- Service Oriented Architecture - when an application is
made of components connected across a network.
13.8 Exercises
Exercise 1
Change the program that retrieves twitter data
(twitter2.py) to also
print out the location for each of the friends
indented under the name by two spaces as follows:
Enter Twitter Account:drchuck
Retrieving http://api.twitter.com/l/statuses/friends/drchuck.xml
Retrieved 194533 characters.
steve_coppin
Kent, UK
Looking forward to some "oh no the markets closed,
davidkocher
Bern
@MikeGrace If possible please post a detailed bug
hrheingold
San Francisco Bay Area
RT @barrywellman: Lovely AmBerhSci Internet & Comm
huge_idea
Boston, MA
@drchuck #cnx2010 misses you, too. Thanks for co